| 2019 |
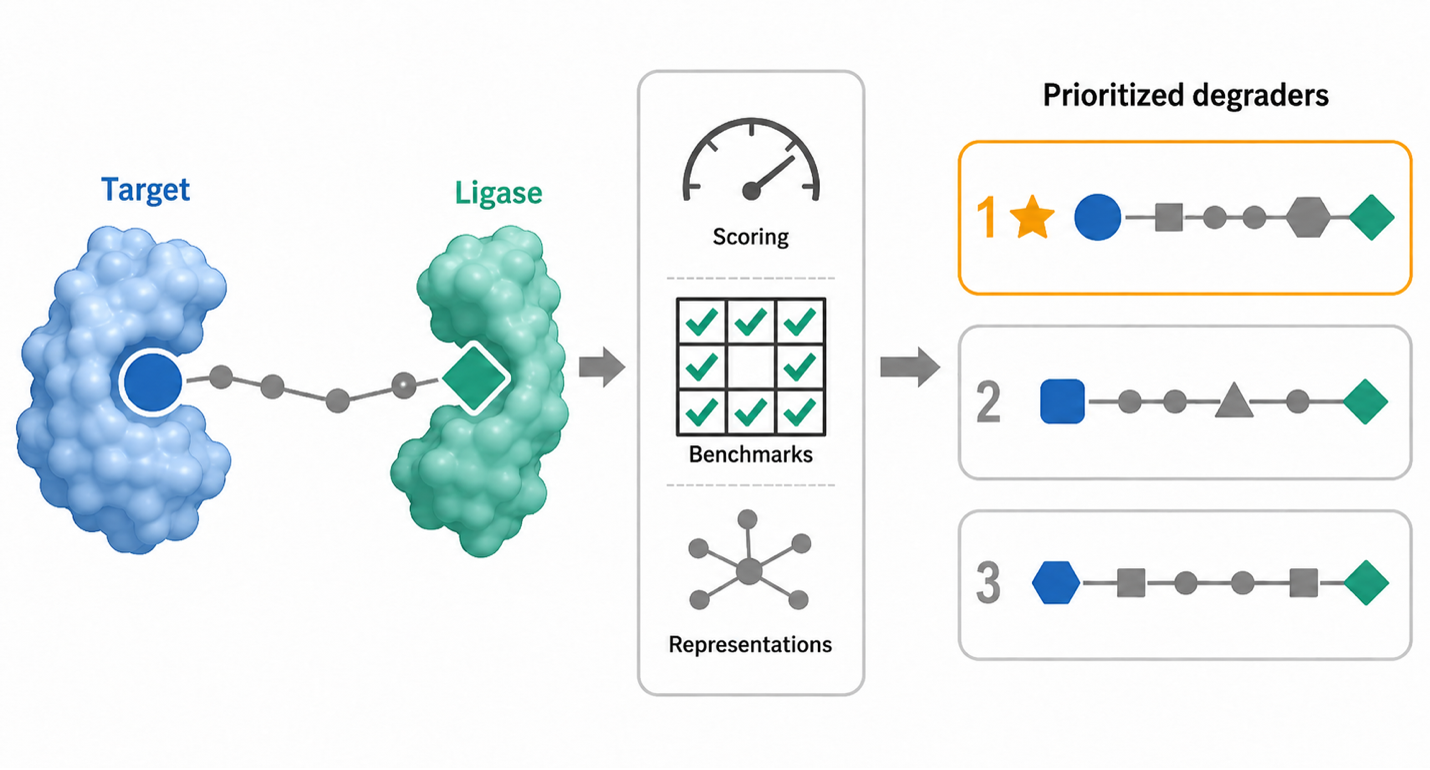
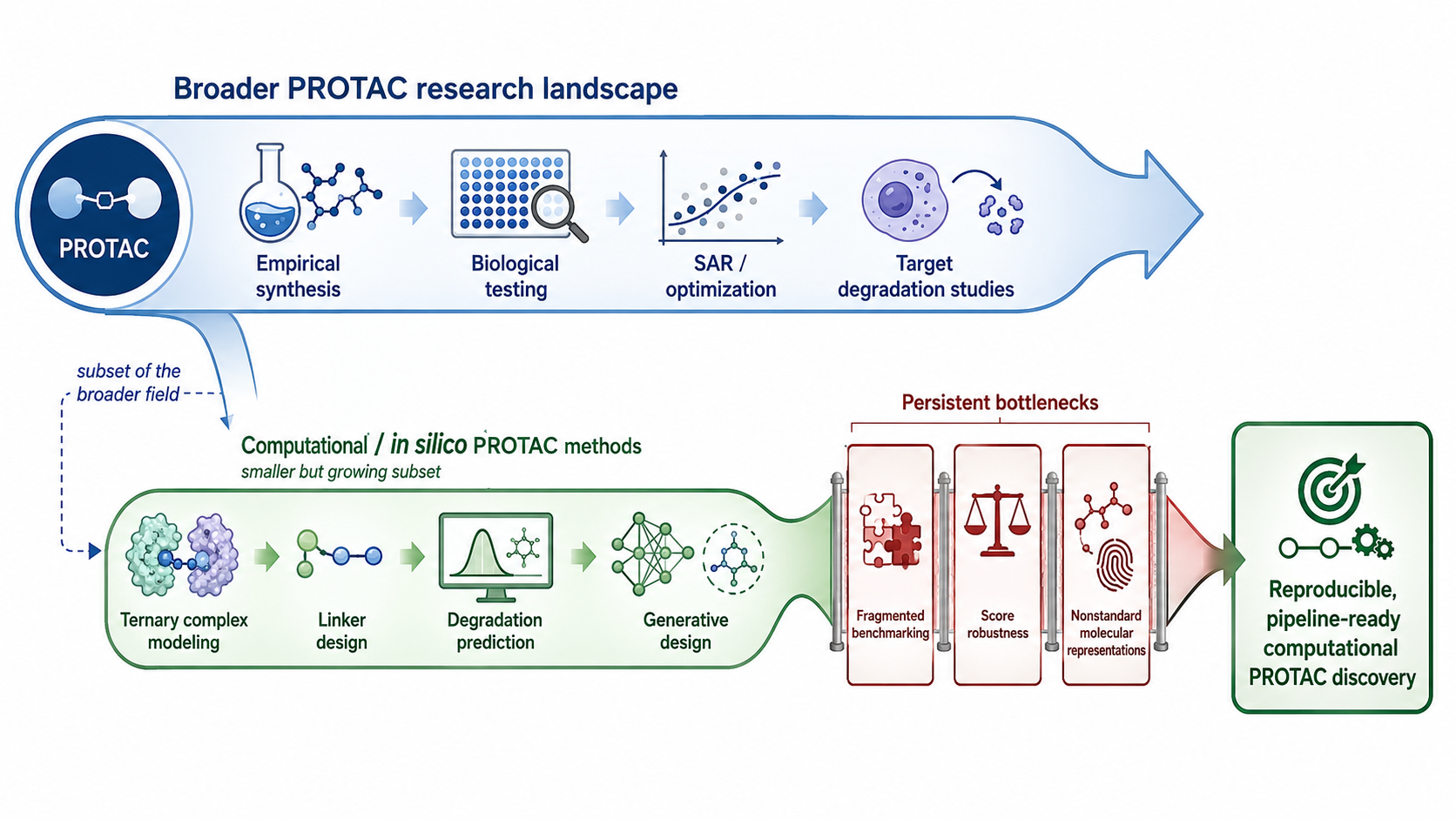
In silico ternary docking |
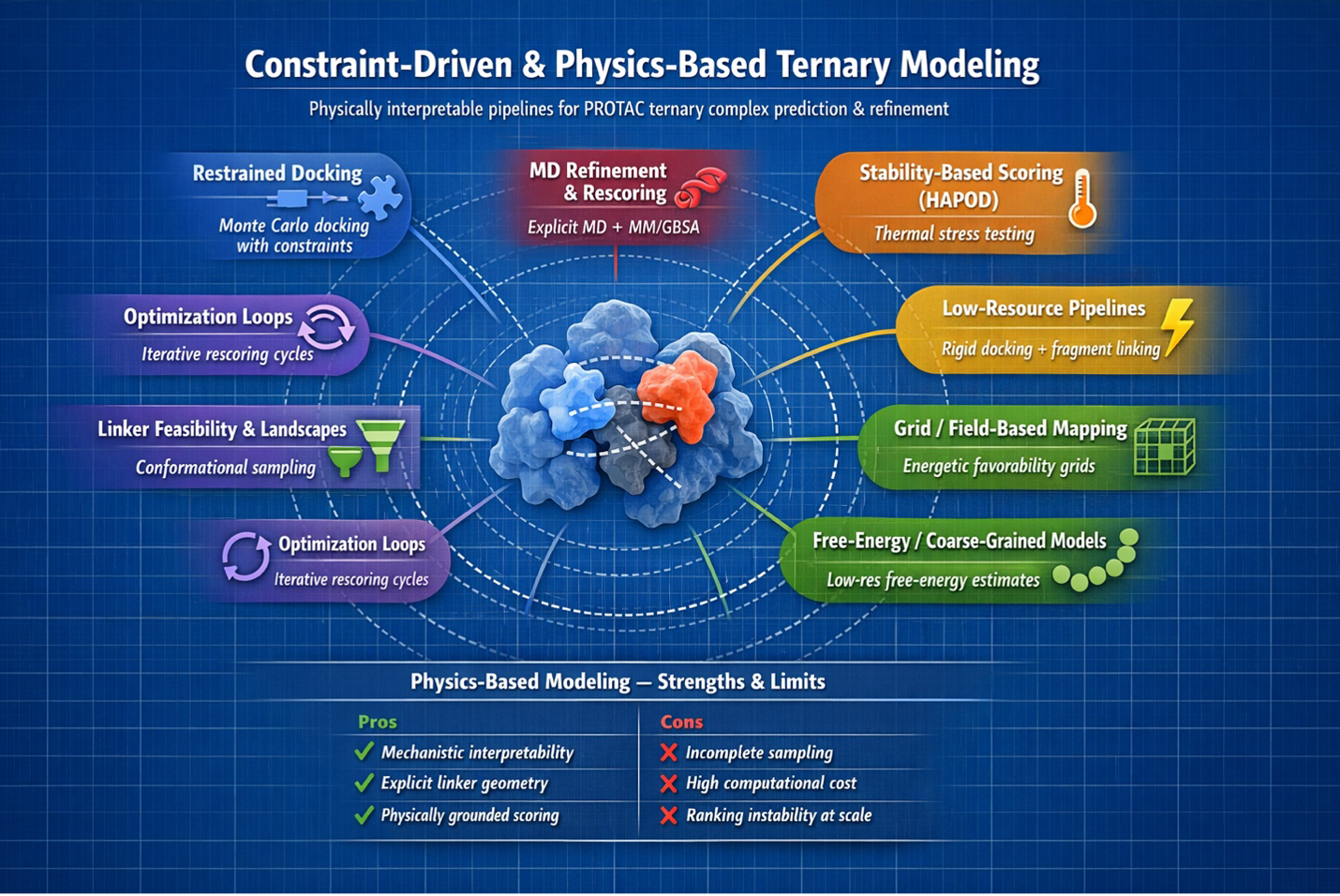
Early Monte Carlo plus protein-protein docking workflows showed that ternary pose generation was feasible and useful for initial geometry exploration. |
Recovered some near-native poses, but scoring produced many false positives and was not robust enough for confident ranking. |
| 2020 |
PRosettaC |
Anchor-constrained Rosetta docking improves geometry-aware ternary construction and supports rational linker SAR interpretation. |
Needs reliable anchor definitions and prior structural knowledge; performance falls when those assumptions are wrong. |
| 2021 |
MD-refined ternary modeling |
Rosetta or docking poses can be relaxed in explicit solvent, then inspected with MM/GBSA-like rescoring and cooperativity analysis. |
Computationally expensive and still sensitive to imperfect scoring functions. |
| 2022 |
HAPOD scoring |
Stress-tests pose persistence with heating-accelerated MD instead of trusting one minimized snapshot. |
Requires repeated MD runs and can be force-field sensitive. |
| 2022 |
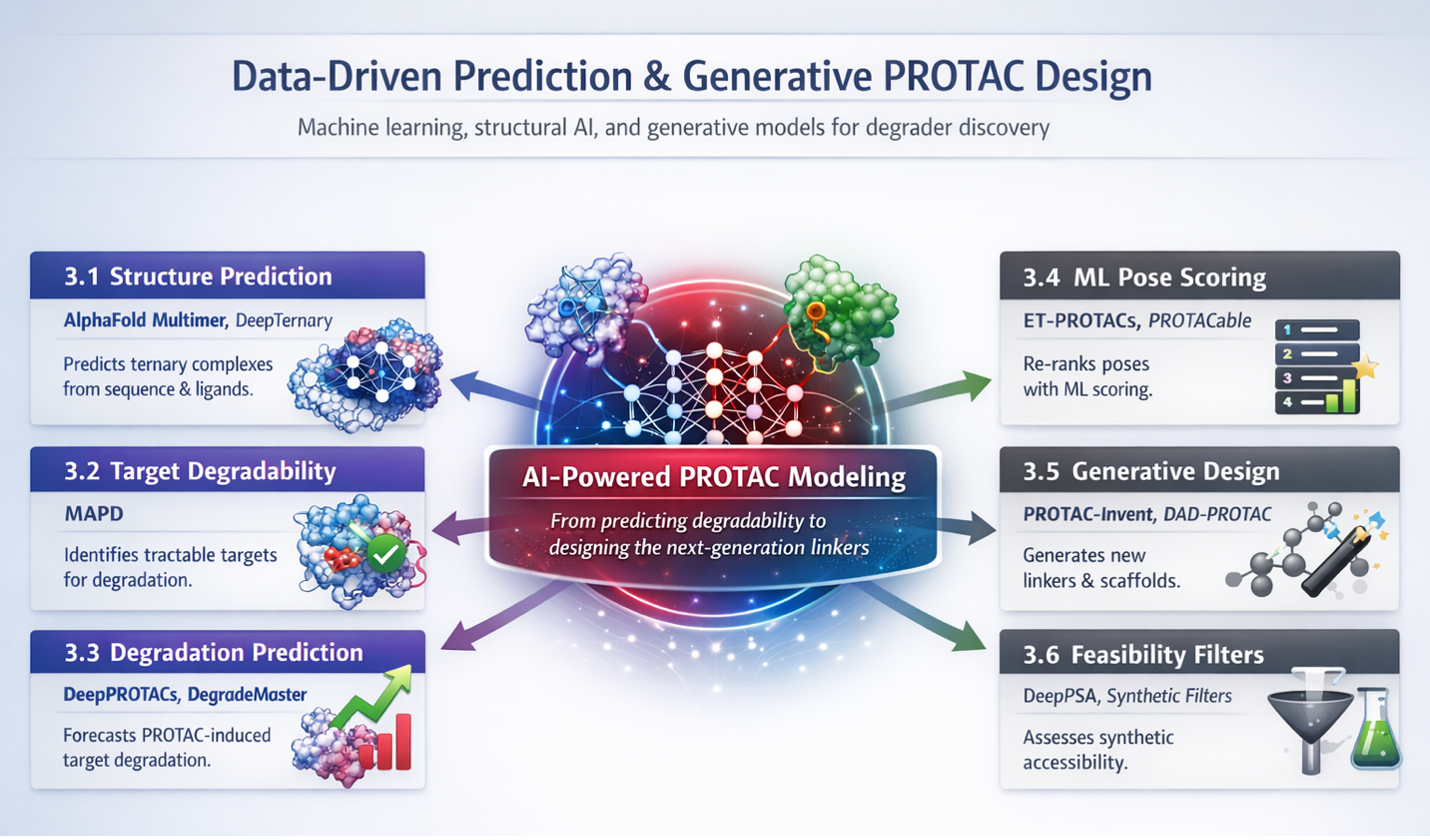
MAPD |
Target-level degradability or tractability prediction helps decide whether a protein is a plausible degradation candidate at all. |
Not candidate-PROTAC-specific; it scores target biology more than degrader chemistry. |
| 2022 |
DeepPROTACs |
Supervised degradation prediction can triage candidate molecules from molecular and protein features. |
Outcome quality depends heavily on training labels, assay context, and domain coverage. |
| 2022 |
Graph-based generative models |
Can propose new degraders or optimize candidate chemistry across large design spaces. |
Generated outputs are only as good as the predictive model and constraints guiding them. |
| 2023 |
Coarse-grained cooperativity |
Useful for understanding linker-length and protein-shape trends in ternary cooperativity. |
Interpretive rather than atomistically precise for a specific medicinal-chemistry decision. |
| 2023 |
Energy landscape mapping |
CCD-style linker placement and energy or solvation landscapes reveal which protein orientations are physically bridgeable. |
Provides thermodynamic understanding but is not a standalone docking engine. |
| 2023 |
PROTAC-Invent |
3D generative linker design expands beyond empirical linker sets and proposes new bridge chemotypes. |
Generated linkers still need structure, property, and activity validation. |
| 2023 |
BOTCP |
Bayesian optimization over pose parameters helps when initial ternary docking is ambiguous. |
Search and scoring can still miss the correct pose even after iterative refinement. |
| 2024 |
DegraderTCM |
Lower-resource ternary construction supports broader screens when exhaustive sampling is too expensive. |
Speed comes at the cost of structural nuance and subtle rearrangement capture. |
| 2024 |
PROTACable |
Integrates structure generation and learned activity prediction into a more end-to-end pipeline. |
Still depends on structural templates and model retraining for new target classes. |
| 2024 |
AlphaFold-style ternary adaptations |
Can produce fully automated protein-complex hypotheses with minimal manual setup. |
Often cannot enforce actual PROTAC geometry and may misorient complexes or overtrust accessory interfaces. |
| 2025 |
DeepTernary |
SE(3)-equivariant ternary structure prediction aims to generate 3D ternary complexes directly from proteins and degrader inputs. |
Needs curated structural training data and may weaken on novel targets, E3 ligases, or scaffolds. |
| 2025 |
DegradeMaster |
Semi-supervised E(3)-equivariant degradation prediction adds geometry-aware features to outcome models. |
Complex training setup and ongoing dependence on curated degradation assay datasets. |
| 2025 |
ProLinker-Generator |
Transformer-style linker generation expands linker chemical space with high novelty and validity. |
Generated linkers still require downstream feasibility, docking, and property filtering. |
| 2025 |
DAD-PROTAC |
Diffusion-style generation adapts general molecule models toward large PROTAC-like linker chemistry. |
Heavier computation and sensitivity to how domain adaptation is calibrated. |
| 2025 |
ET-PROTACs |
Cross-modal learned scoring helps re-rank docking ensembles by pose viability or complex stability. |
It scores existing poses rather than generating them and depends strongly on input-pose quality. |
| 2026 |
SILCS-xTAC |
Grid-based ensemble scoring captures geometric and energetic complementarity across ternary ensembles. |
Score transferability across target, E3, and linker classes still needs broad validation. |
| 2026 |
SE(3)-PROTACs |
Geometry-aware transformer models extend degradation prediction with 3D molecular graphs and protein context. |
Performance still depends on curated labels and may fall under harder out-of-domain evaluation splits. |